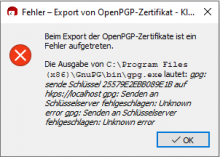
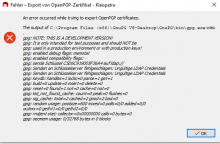
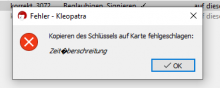
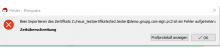
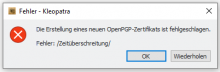
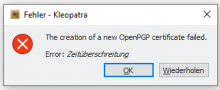
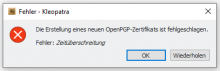
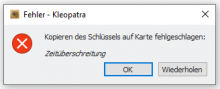
Notices with refresh-keys but I also had this on other places where Gpg Output was used in Kleopatra.
I think that stringFromGpgOutput (I think that is what is called) might be wrong now that GnuPG trys to always output UTF-8
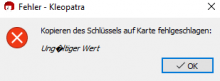
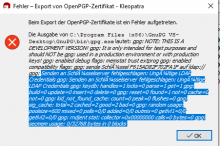
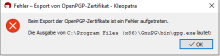
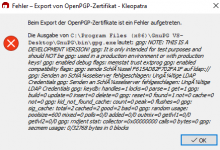
Reproducable with German l10n and refresh-keys. Both the output window and the error message (if there is an error) have broken umlauts.